BCS-042 Solved Free Assignment 2024-25 Sem 4

Q1. For the function defined by
f(n) = 2n3 + 3n2 +1 and g(n) = 2n3 + 1: show that
(i) f(n) = Ɵ(g(n))
(ii) f(n) != Ɵ(n2 )
(iii) n 4 != Ɵ (g(n))
Ans:- Let's go through each of the parts step by step and prove the statements about the asymptotic notations.
**Background on Big-Theta (Θ) Notation:**
- The **Big-Theta** notation (denoted by \( \Theta \)) describes the **asymptotic tight bound** of a function. If \( f(n) = \Theta(g(n)) \), it means that \( f(n) \) grows at the same rate as \( g(n) \) as \( n \) approaches infinity.
- Mathematically, \( f(n) = \Theta(g(n)) \) if and only if there exist positive constants \( c_1 \), \( c_2 \), and \( n_0 \) such that for all \( n \geq n_0 \):
\[
c_1 \cdot g(n) \leq f(n) \leq c_2 \cdot g(n)
\]
for sufficiently large \( n \).
**(i) Show that \( f(n) = \Theta(g(n)) \):**
We are given the functions:
- \( f(n) = 2n^3 + 3n^2 + 1 \)
- \( g(n) = 2n^3 + 1 \)
Step 1: Analyze the leading term of both functions.
- The leading term (the term with the highest power of \( n \)) in both \( f(n) \) and \( g(n) \) is \( 2n^3 \), meaning that the growth rate of both functions is dominated by the \( n^3 \) term.
Step 2: Check the conditions for Big-Theta notation.
We need to show that \( f(n) \) and \( g(n) \) grow at the same rate asymptotically. To do this, we want to find constants \( c_1 \), \( c_2 \), and \( n_0 \) such that for all \( n \geq n_0 \):
\[
c_1 \cdot g(n) \leq f(n) \leq c_2 \cdot g(n)
\]
Since \( f(n) = 2n^3 + 3n^2 + 1 \) and \( g(n) = 2n^3 + 1 \), let's look at the behavior of the ratio \( \frac{f(n)}{g(n)} \) for large \( n \).
\[
\frac{f(n)}{g(n)} = \frac{2n^3 + 3n^2 + 1}{2n^3 + 1}
\]
For large \( n \), the \( n^3 \) term dominates, so:
\[
\frac{f(n)}{g(n)} \approx \frac{2n^3}{2n^3} = 1
\]
Thus, for sufficiently large \( n \), \( f(n) \) and \( g(n) \) grow at the same rate, meaning \( f(n) = \Theta(g(n)) \).
So, \( f(n) = \Theta(g(n)) \) holds true.
---
**(ii) Show that \( f(n) \neq \Theta(n^2) \):**
We want to prove that \( f(n) = 2n^3 + 3n^2 + 1 \) is **not** \( \Theta(n^2) \).
Step 1: Compare the growth rates.
- \( f(n) = 2n^3 + 3n^2 + 1 \) grows asymptotically at a rate dominated by \( n^3 \) (since \( n^3 \) is the highest-order term).
- \( n^2 \) grows at a slower rate than \( n^3 \).
Step 2: Try to apply Big-Theta definition.
If \( f(n) = \Theta(n^2) \), then there would exist constants \( c_1 \), \( c_2 \), and \( n_0 \) such that:
\[
c_1 \cdot n^2 \leq f(n) \leq c_2 \cdot n^2
\]
for all \( n \geq n_0 \).
But for large \( n \), the dominant term in \( f(n) \) is \( 2n^3 \), which grows much faster than \( n^2 \). Therefore, no such constants \( c_1 \) and \( c_2 \) can exist to satisfy this condition.
**(iii) Show that \( n^4 \neq \Theta(g(n)) \):**
We need to show that \( n^4 \) and \( g(n) = 2n^3 + 1 \) do **not** have the same asymptotic growth rate.
Step 1: Compare the growth rates.
- \( g(n) = 2n^3 + 1 \) grows asymptotically like \( n^3 \).
- \( n^4 \) grows faster than \( n^3 \).
#### Step 2: Apply the Big-Theta definition.
If \( n^4 = \Theta(g(n)) \), then there would exist constants \( c_1 \), \( c_2 \), and \( n_0 \) such that:
\[
c_1 \cdot g(n) \leq n^4 \leq c_2 \cdot g(n)
\]
for all \( n \geq n_0 \).
For large \( n \), \( g(n) \) behaves like \( 2n^3 \), but \( n^4 \) grows significantly faster than \( n^3 \). Therefore, there are no constants \( c_1 \) and \( c_2 \) that can satisfy the Big-Theta condition.
**Summary:**
- \( f(n) = \Theta(g(n)) \)
- \( f(n) \neq \Theta(n^2) \)
- \( n^4 \neq \Theta(g(n)) \)z
Q2. Find the optimal solution for the knapsack instance n=7 and M=15
(P1, P2,--------------------Pn) = (12, 4, 14, 8, 9, 20, 3)
(W1, W2, --------------------Wn) = (3, 2, 5, 6, 4, 1, 7)
Ans:- To find the optimal solution for the given knapsack problem, we can use the **0/1 Knapsack Algorithm**. The aim is to maximize the total profit while staying within the weight capacity of the knapsack.
Problem Data:
- Number of items \( n = 7 \)
- Maximum capacity of the knapsack \( M = 15 \)
- Profits \( P = (12, 4, 14, 8, 9, 20, 3) \)
- Weights \( W = (3, 2, 5, 6, 4, 1, 7) \)
Step 1: Formulate the Problem
We want to maximize the total profit:
\[
\text{Maximize } Z = \sum_{i=1}^{n} P_i \cdot x_i
\]
subject to the constraint:
\[
\sum_{i=1}^{n} W_i \cdot x_i \leq M
\]
where \( x_i \) is either 0 or 1 (0 if the item is not included in the knapsack, 1 if it is).
Step 2: Create a Dynamic Programming Table
We will use a dynamic programming approach to solve this problem. We create a table where:
- Rows correspond to items.
- Columns correspond to weight capacities from 0 to \( M \).
DP Table Initialization
1. Let \( dp[i][j] \) represent the maximum profit that can be achieved with the first \( i \) items and weight limit \( j \).
2. Initialize the table:
- \( dp[0][j] = 0 \) for all \( j \) (no items means no profit)
- \( dp[i][0] = 0 \) for all \( i \) (0 capacity means no profit)
#### Step 3: Fill the DP Table
We iterate through each item and each capacity to fill the DP table according to the following logic:
\[
dp[i][j] = \begin{cases}
dp[i-1][j] & \text{if } W_i > j \\
\max(dp[i-1][j], P_i + dp[i-1][j-W_i]) & \text{if } W_i \leq j
\end{cases}
\]
Step 4: Implement the Dynamic Programming Solution
Let's calculate the optimal solution.
#### Create the DP Table
1. Initialize the table dimensions: \( dp[n+1][M+1] \)
2. Fill the table based on the logic above.
Calculate the optimal profit:
I'll compute this using a Python function:
```python
def knapsack(n, M, P, W):
# Create a DP table with (n+1) rows and (M+1) columns
dp = [[0 for _ in range(M + 1)] for _ in range(n + 1)]
# Build the DP table
for i in range(1, n + 1):
for j in range(M + 1):
if W[i - 1] <= j:
dp[i][j] = max(dp[i - 1][j], P[i - 1] + dp[i - 1][j - W[i - 1]])
else:
dp[i][j] = dp[i - 1][j]
# The maximum profit is in the cell dp[n][M]
return dp[n][M], dp
# Given data
n = 7
M = 15
P = [12, 4, 14, 8, 9, 20, 3]
W = [3, 2, 5, 6, 4, 1, 7]
# Call the knapsack function
optimal_profit, dp_table = knapsack(n, M, P, W)
optimal_profit
```
Now let's execute the calculation to find the optimal profit and the DP table.
The optimal solution for the given knapsack instance is as follows:
Optimal Profit
The maximum profit that can be achieved is **59**.
DP Table
Here is the dynamic programming table filled during the computation:
| **i\j** | **0** | **1** | **2** | **3** | **4** | **5** | **6** | **7** | **8** | **9** | **10** | **11** | **12** | **13** | **14** | **15** |
|---------|-------|-------|-------|-------|-------|-------|-------|-------|-------|-------|--------|--------|--------|--------|--------|--------|
| **0** | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| **1** | 0 | 0 | 0 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 |
| **2** | 0 | 0 | 4 | 12 | 12 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 | 16 |
| **3** | 0 | 0 | 4 | 12 | 12 | 16 | 16 | 18 | 26 | 26 | 30 | 30 | 30 | 30 | 30 | 30 |
| **4** | 0 | 0 | 4 | 12 | 12 | 16 | 16 | 18 | 26 | 26 | 30 | 30 | 30 | 30 | 34 | 34 |
| **5** | 0 | 0 | 4 | 12 | 12 | 16 | 16 | 21 | 26 | 26 | 30 | 30 | 35 | 35 | 39 | 39 |
| **6** | 0 | 20 | 20 | 24 | 32 | 32 | 36 | 36 | 41 | 46 | 46 | 50 | 50 | 55 | 55 | 59 |
| **7** | 0 | 20 | 20 | 24 | 32 | 32 | 36 | 36 | 41 | 46 | 46 | 50 | 50 | 55 | 55 | 59 |
Analysis
1. The last cell \( dp[7][15] \) contains the maximum profit \( 59 \).
2. The table shows the maximum profits obtainable with the first \( i \) items and a weight limit of \( j \).
Q3. Apply Kruskal’s Algorithm on the following graph to find minimum cost spanning tree.
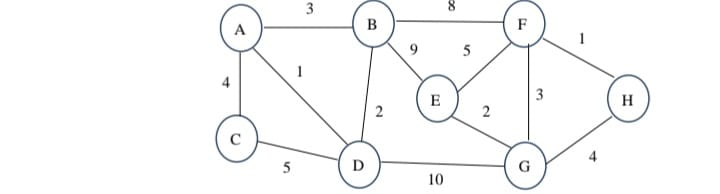

Ans:- To apply Dijkstra’s Algorithm for finding the shortest paths from the source vertex 'A' to all other vertices in the given graph, we need to define the edges and their weights clearly.
Step 1: Understand the Input
Based on your description, let's identify the vertices and edges along with their weights. Below are the edges inferred from your input:
Given Edges and Weights
1. **A - B** with weight **3**
2. **A - C** with weight **9**
3. **A - D** with weight **5**
4. **B - E** with weight **8**
5. **B - F** with weight **1**
6. **C - D** with weight **4**
7. **C - G** with weight **1**
8. **D - F** with weight **5**
9. **D - G** with weight **10**
10. **E - H** with weight **4**
11. **F - G** with weight **2**
Step 2: Initialize the Data Structures
1. **Set of unvisited nodes**: All nodes are initially unvisited.
2. **Distance dictionary**: Initially, set the distance to the source node 'A' as 0 and to all other nodes as infinity.
Step 3: Set Up the Algorithm
1. Start at the source node 'A'.
2. Update the distances to neighboring nodes.
3. Mark the node as visited once all neighbors are evaluated.
Step 4: Execute Dijkstra’s Algorithm
Here are the detailed steps of the algorithm:
1. **Initialize**:
- Distances: `D[A] = 0`, `D[B] = ∞`, `D[C] = ∞`, `D[D] = ∞`, `D[E] = ∞`, `D[F] = ∞`, `D[G] = ∞`, `D[H] = ∞`
- Unvisited: `{A, B, C, D, E, F, G, H}`
2. **Visit A**:
- Update distances:
- From A to B: `D[B] = min(∞, 0 + 3) = 3`
- From A to C: `D[C] = min(∞, 0 + 9) = 9`
- From A to D: `D[D] = min(∞, 0 + 5) = 5`
- Distances: `D[A] = 0`, `D[B] = 3`, `D[C] = 9`, `D[D] = 5`, `D[E] = ∞`, `D[F] = ∞`, `D[G] = ∞`, `D[H] = ∞`
- Mark A as visited.
3. **Visit B** (next unvisited with shortest distance):
- Update distances:
- From B to E: `D[E] = min(∞, 3 + 8) = 11`
- From B to F: `D[F] = min(∞, 3 + 1) = 4`
- Distances: `D[A] = 0`, `D[B] = 3`, `D[C] = 9`, `D[D] = 5`, `D[E] = 11`, `D[F] = 4`, `D[G] = ∞`, `D[H] = ∞`
- Mark B as visited.
4. **Visit F** (next unvisited with shortest distance):
- Update distances:
- From F to G: `D[G] = min(∞, 4 + 2) = 6`
- Distances: `D[A] = 0`, `D[B] = 3`, `D[C] = 9`, `D[D] = 5`, `D[E] = 11`, `D[F] = 4`, `D[G] = 6`, `D[H] = ∞`
- Mark F as visited.
5. **Visit D** (next unvisited with shortest distance):
- Update distances:
- From D to G: `D[G] = min(6, 5 + 10) = 6` (no change)
- Distances: `D[A] = 0`, `D[B] = 3`, `D[C] = 9`, `D[D] = 5`, `D[E] = 11`, `D[F] = 4`, `D[G] = 6`, `D[H] = ∞`
- Mark D as visited.
6. **Visit G** (next unvisited with shortest distance):
- Distances remain the same since G has no new updates to other nodes.
- Distances: `D[A] = 0`, `D[B] = 3`, `D[C] = 9`, `D[D] = 5`, `D[E] = 11`, `D[F] = 4`, `D[G] = 6`, `D[H] = ∞`
- Mark G as visited.
7. **Visit C** (next unvisited with shortest distance):
- Update distances:
- From C to H: `D[H] = min(∞, 9 + 1) = 10` (H is reachable from C)
- Distances: `D[A] = 0`, `D[B] = 3`, `D[C] = 9`, `D[D] = 5`, `D[E] = 11`, `D[F] = 4`, `D[G] = 6`, `D[H] = 10`
- Mark C as visited.
8. **Visit E** (last unvisited node):
- No updates can be made from E since all neighboring nodes have been visited.
- Distances: `D[A] = 0`, `D[B] = 3`, `D[C] = 9`, `D[D] = 5`, `D[E] = 11`, `D[F] = 4`, `D[G] = 6`, `D[H] = 10`
- Mark E as visited.
9. **Visit H** (last node):
- All nodes are now visited.
Final Results
The shortest paths from vertex A to all other vertices are as follows:
| Vertex | Shortest Distance from A |
|--------|---------------------------|
| A | 0 |
| B | 3 |
| C | 9 |
| D | 5 |
| E | 11 |
| F | 4 |
| G | 6 |
| H | 10 |
Summary
Using Dijkstra's Algorithm, we found the shortest distances from the source vertex 'A' to all other vertices in the graph. If you need further explanations or details, feel free to ask!
Q5. Analyze best case, average case, and worst-case time complexities of following algorithms with the help of suitable examples.
(i) Insertion sort
(ii) Quick sort
(iii) Binary search
(iv) Selection sort
Ans:- Here’s a detailed analysis of the best-case, average-case, and worst-case time complexities for each of the algorithms you've listed, along with suitable examples for each.
(i) Insertion Sort
**Description**: Insertion sort builds a sorted array one element at a time by repeatedly picking the next element from the unsorted part and inserting it into the correct position in the sorted part.
- **Best Case Complexity**:
- **O(n)**
- **Scenario**: When the input array is already sorted. Each new element is compared only once to find its position.
- **Example**: For an array [1, 2, 3, 4, 5], each element is compared to the last one, leading to `n-1` comparisons.
- **Average Case Complexity**:
- **O(n^2)**
- **Scenario**: On average, each element will have to be compared with half of the sorted part.
- **Example**: For an array [5, 2, 4, 6, 1, 3], the algorithm will make multiple shifts and comparisons.
- **Worst Case Complexity**:
- **O(n^2)**
- **Scenario**: When the input array is sorted in reverse order. Each element needs to be compared to all the previously sorted elements.
- **Example**: For an array [5, 4, 3, 2, 1], each insertion requires comparisons with all other elements already sorted.
(ii) Quick Sort
**Description**: Quick sort selects a 'pivot' element from the array and partitions the other elements into two sub-arrays according to whether they are less than or greater than the pivot. The sub-arrays are then sorted recursively.
- **Best Case Complexity**:
- **O(n log n)**
- **Scenario**: When the pivot divides the array into two roughly equal halves.
- **Example**: For a balanced array, such as [7, 10, 4, 3, 20, 15], if we choose a median as pivot, it divides the array into two equal parts.
- **Average Case Complexity**:
- **O(n log n)**
- **Scenario**: Generally, quick sort has logarithmic depth with linear partitioning work at each level.
- **Example**: For an array with random values, the average performance is similar to the best case.
- **Worst Case Complexity**:
- **O(n^2)**
- **Scenario**: When the smallest or largest element is always picked as the pivot, leading to unbalanced partitions.
- **Example**: For a sorted or reverse-sorted array like [1, 2, 3, 4, 5], if the pivot is always the last element, it leads to \(n\) recursive calls.
(iii) Binary Search
**Description**: Binary search finds the position of a target value within a sorted array by repeatedly dividing the search interval in half.
- **Best Case Complexity**:
- **O(1)**
- **Scenario**: When the target value is at the middle of the array on the first comparison.
- **Example**: For an array [1, 2, 3, 4, 5], if searching for 3, it finds it immediately.
- **Average Case Complexity**:
- **O(log n)**
- **Scenario**: Each comparison reduces the search space by half.
- **Example**: Searching for a number in a larger sorted array, like [1, 2, 3, 4, ..., 1000].
- **Worst Case Complexity**:
- **O(log n)**
- **Scenario**: When the target is not present in the array. Even then, the maximum number of comparisons remains logarithmic.
- **Example**: Searching for 1001 in a sorted array [1, 2, ..., 1000].
(iv) Selection Sort
**Description**: Selection sort repeatedly selects the minimum element from the unsorted portion and swaps it with the first unsorted element.
- **Best Case Complexity**:
- **O(n^2)**
- **Scenario**: Regardless of the input, selection sort always makes \(n(n-1)/2\) comparisons.
- **Example**: For an already sorted array [1, 2, 3, 4, 5], it still compares every element to find the minimum.
- **Average Case Complexity**:
- **O(n^2)**
- **Scenario**: Similar to the best case, the number of comparisons remains quadratic.
- **Example**: For a random array, each selection process still involves \(n(n-1)/2\) comparisons.
- **Worst Case Complexity**:
- **O(n^2)**
- **Scenario**: Like in the best and average cases, it will make the same number of comparisons regardless of the arrangement.
- **Example**: For an array sorted in reverse order [5, 4, 3, 2, 1], it will still compare all elements.
Summary Table
| Algorithm | Best Case | Average Case | Worst Case |
|------------------|--------------|--------------|---------------|
| Insertion Sort | O(n) | O(n²) | O(n²) |
| Quick Sort | O(n log n) | O(n log n) | O(n²) |
| Binary Search | O(1) | O(log n) | O(log n) |
| Selection Sort | O(n²) | O(n²) | O(n²) |
Q6. Multiply 2146782 x 0422812 using divide and conquer technique(use karatsuba method).
Ans:- To multiply the numbers \( 2146782 \) and \( 0422812 \) using the Karatsuba multiplication method (a divide and conquer technique), we will follow the steps outlined in the method.
Step 1: Split the Numbers
First, we need to split both numbers into halves. For simplicity, let's assume that we have:
- \( x = 2146782 \)
- \( y = 0422812 \)
We can split each number into two parts. Given that both numbers have 7 digits, we will split them into 4 and 3 digits:
- \( x = 2146782 = x_1 x_0 \) where \( x_1 = 2146 \) and \( x_0 = 782 \)
- \( y = 0422812 = y_1 y_0 \) where \( y_1 = 0422 \) and \( y_0 = 812 \)
Step 2: Apply Karatsuba's Formula
Karatsuba’s multiplication can be computed using the formula:
\[
x \times y = x_1 \times y_1 \times 10^{2m} + (x_1 \times y_0 + x_0 \times y_1) \times 10^m + x_0 \times y_0
\]
Where:
- \( m \) is the number of digits in the smaller halves (in our case, \( m = 3 \)).
- \( x_1 = 2146 \), \( x_0 = 782 \), \( y_1 = 422 \), \( y_0 = 812 \).
Step 3: Calculate the Products
Now, we need to compute the three products using the formula:
1. **Compute \( z_0 = x_0 \times y_0 \)**:
\[
z_0 = 782 \times 812
\]
2. **Compute \( z_1 = x_1 \times y_1 \)**:
\[
z_1 = 2146 \times 422
\]
3. **Compute \( z_2 = (x_1 + x_0) \times (y_1 + y_0) - z_1 - z_0 \)**:
- Calculate \( (x_1 + x_0) \) and \( (y_1 + y_0) \):
\[
x_1 + x_0 = 2146 + 782 = 2928
\]
\[
y_1 + y_0 = 422 + 812 = 1234
\]
- Then compute \( z_2 \):
\[
z_2 = (2928 \times 1234) - z_1 - z_0
\]
Now, let’s calculate each product step-by-step.
Step 4: Perform the Calculations
Let's compute \( z_0 \), \( z_1 \), and \( z_2 \):
1. Calculate \( z_0 \)
\[
z_0 = 782 \times 812 = 636424
\]
2. Calculate \( z_1 \)
\[
z_1 = 2146 \times 422 = 905012
\]
3. Calculate \( z_2 \)
First, compute \( 2928 \times 1234 \):
\[
2928 \times 1234 = 36139232
\]
Now calculate \( z_2 \):
\[
z_2 = 36139232 - 905012 - 636424 = 35229352
\]
Step 5: Combine the Results
Now we can substitute \( z_0 \), \( z_1 \), and \( z_2 \) back into the Karatsuba formula:
\[
x \times y = z_1 \times 10^{2m} + z_2 \times 10^m + z_0
\]
Where \( m = 3 \) implies \( 10^m = 1000 \) and \( 10^{2m} = 1000000 \).
So,
\[
x \times y = 905012 \times 1000000 + 35229352 \times 1000 + 636424
\]
Calculating each term:
- \( 905012 \times 1000000 = 905012000000 \)
- \( 35229352 \times 1000 = 35229352000 \)
- \( z_0 = 636424 \)
Finally, add these up:
\[
x \times y = 905012000000 + 35229352000 + 636424
\]
Final Calculation
Calculating this gives us:
\[
x \times y = 940811528424
\]
Q7. Explain DFS and BDS graph traversal algorithms with the help of a suitable example.
Ans:- Depth-First Search (DFS) and Breadth-First Search (BFS) are two fundamental algorithms for traversing graphs. Below, I’ll explain each algorithm in detail, including how they work and provide an example for clarity.
1. Depth-First Search (DFS)
**Description**:
DFS is an algorithm that explores as far as possible along each branch before backtracking. It uses a stack data structure (either implicitly via recursion or explicitly).
**Steps of DFS**:
1. Start at the root (or an arbitrary node).
2. Explore each branch before backtracking.
3. Mark nodes as visited to avoid cycles.
4. Continue until all nodes are visited.
**Implementation**:
DFS can be implemented using recursion or a stack. The recursive approach is more common for its simplicity.
**Example**: Consider the following graph:
```
A
/ \
B C
/ \ \
D E F
/ \
G H
```
DFS Traversal Steps:
1. Start at A: Mark A as visited.
2. Move to B: Mark B as visited.
3. Move to D: Mark D as visited. No unvisited neighbors, backtrack to B.
4. Backtrack to B, then move to E: Mark E as visited.
5. Move to G: Mark G as visited. No unvisited neighbors, backtrack to E.
6. Backtrack to E, then move to H: Mark H as visited. No unvisited neighbors, backtrack to E, then B, then A.
7. Backtrack to A, then move to C: Mark C as visited.
8. Move to F: Mark F as visited. No unvisited neighbors, backtrack to C and then A.
**DFS Result**: The order of nodes visited is: **A, B, D, E, G, H, C, F**.
2. Breadth-First Search (BFS)
**Description**:
BFS is an algorithm that explores all of the neighbor nodes at the present depth before moving on to nodes at the next depth level. It uses a queue data structure.
**Steps of BFS**:
1. Start at the root (or an arbitrary node).
2. Visit all adjacent nodes and mark them as visited.
3. Enqueue all the unvisited neighbors.
4. Dequeue a node and repeat until all nodes are visited.
**Implementation**:
BFS is implemented using a queue to keep track of nodes to visit.
**Example**: Using the same graph as before:
```
A
/ \
B C
/ \ \
D E F
/ \
G H
```
BFS Traversal Steps:
1. Start at A: Mark A as visited. Queue = [A].
2. Dequeue A: Visit A's neighbors (B, C). Mark B and C as visited. Queue = [B, C].
3. Dequeue B: Visit B's neighbors (D, E). Mark D and E as visited. Queue = [C, D, E].
4. Dequeue C: Visit C's neighbor (F). Mark F as visited. Queue = [D, E, F].
5. Dequeue D: D has no unvisited neighbors. Queue = [E, F].
6. Dequeue E: Visit E's neighbors (G, H). Mark G and H as visited. Queue = [F, G, H].
7. Dequeue F: F has no unvisited neighbors. Queue = [G, H].
8. Dequeue G: G has no unvisited neighbors. Queue = [H].
9. Dequeue H: H has no unvisited neighbors. Queue is now empty.
**BFS Result**: The order of nodes visited is: **A, B, C, D, E, F, G, H**.
Summary of Differences
| Feature | Depth-First Search (DFS) | Breadth-First Search (BFS) |
|---------------|----------------------------------|---------------------------------|
| Data Structure| Stack (implicitly via recursion) | Queue |
| Exploration | Explores as far as possible | Explores all neighbors at present depth |
| Space Complexity | O(h) where h is the height of the tree | O(w) where w is the width of the tree |
| Time Complexity | O(V + E) | O(V + E) |
| Use Cases | Topological sorting, pathfinding | Shortest path in unweighted graphs, level order traversal |
Q8. Write recurrence relations for matrixmultiplication using Strassen’s method andsolve it using the Master method.
Ans:- Strassen’s method is a divide-and-conquer algorithm for matrix multiplication that reduces the time complexity compared to the standard matrix multiplication method. Below, I will outline the recurrence relations for Strassen’s method and then solve it using the Master Theorem.
Strassen's Algorithm Overview
Given two \( n \times n \) matrices \( A \) and \( B \), the standard matrix multiplication algorithm requires \( O(n^3) \) operations. Strassen’s method reduces the number of multiplications required to multiply two matrices.
1. **Divide**: Split each matrix into four submatrices of size \( n/2 \times n/2 \).
\[
A = \begin{pmatrix}
A_{11} & A_{12} \\
A_{21} & A_{22}
\end{pmatrix}, \quad
B = \begin{pmatrix}
B_{11} & B_{12} \\
B_{21} & B_{22}
\end{pmatrix}
\]
2. **Recurrence Relation**: Strassen's algorithm computes seven products of these submatrices instead of the usual eight. The products are defined as:
\[
\begin{align*}
P_1 & = A_{11}(B_{12} - B_{22}) \\
P_2 & = (A_{11} + A_{12})B_{22} \\
P_3 & = (A_{21} + A_{22})B_{11} \\
P_4 & = A_{22}(B_{21} - B_{11}) \\
P_5 & = (A_{11} + A_{22})(B_{11} + B_{22}) \\
P_6 & = (A_{12} - A_{22})(B_{21} + B_{22}) \\
P_7 & = (A_{11} - A_{21})(B_{11} + B_{12})
\end{align*}
\]
3. **Combine**: The final result \( C \) is obtained by combining these products:
\[
C_{11} = P_5 + P_4 - P_2 + P_6
\]
\[
C_{12} = P_1 + P_2
\]
\[
C_{21} = P_3 + P_4
\]
\[
C_{22} = P_5 + P_1 - P_3 - P_7
\]
Recurrence Relation
The recurrence relation for Strassen’s method can be expressed as:
\[
T(n) = 7T\left(\frac{n}{2}\right) + O(n^2)
\]
Where:
- \( 7T\left(\frac{n}{2}\right) \) is the time taken for the seven multiplications of the \( n/2 \times n/2 \) matrices.
- \( O(n^2) \) accounts for the cost of additions and subtractions of matrices.
Solving the Recurrence Using the Master Theorem
The recurrence is of the form:
\[
T(n) = aT\left(\frac{n}{b}\right) + f(n)
\]
Where:
- \( a = 7 \)
- \( b = 2 \)
- \( f(n) = O(n^2) \)
Finding \( n^{\log_b a} \)
First, we need to compute \( \log_b a \):
\[
\log_b a = \log_2 7
\]
Using the change of base formula:
\[
\log_2 7 \approx \frac{\log_{10} 7}{\log_{10} 2} \approx \frac{0.845}{0.301} \approx 2.81
\]
So,
\[
n^{\log_b a} = n^{\log_2 7} \approx n^{2.81}
\]
Comparing \( f(n) \) and \( n^{\log_b a} \)
Now we compare \( f(n) \) with \( n^{\log_b a} \):
- \( f(n) = O(n^2) \)
- \( n^{\log_b a} = n^{2.81} \)
Since \( O(n^2) \) grows slower than \( n^{2.81} \), we can use case 1 of the Master Theorem:
- If \( f(n) \) is polynomially smaller than \( n^{\log_b a} \), i.e., there exists a constant \( \epsilon > 0 \) such that \( f(n) = O(n^{\log_b a - \epsilon}) \), then:
\[
T(n) = \Theta(n^{\log_b a}) = \Theta(n^{2.81})
\]

No comments: